emlファイルから添付ファイルを抽出するスクリプト3 [プログラム]
以前作ったのを改良しました。
複数のファイルをドラッグ&ドロップしても大丈夫です。
emlファイルから添付ファイルを抽出するスクリプト
当該スクリプトをvbsファイルに保存し、複数のemlファイルをドラッグ&ドロップでデスクトップに添付ファイルが保存されます。
添付ファイルは受信日時と件名と添付ファイル名がくっつくようにしています。
*********ここから***************
****************ここまで*****************
複数のファイルをドラッグ&ドロップしても大丈夫です。
emlファイルから添付ファイルを抽出するスクリプト
当該スクリプトをvbsファイルに保存し、複数のemlファイルをドラッグ&ドロップでデスクトップに添付ファイルが保存されます。
添付ファイルは受信日時と件名と添付ファイル名がくっつくようにしています。
*********ここから***************
Option Explicit
Dim EmlFileName
Dim Message,Stm,Attachment,strSub,strDtime
Dim SaveFile,objShell
Set Message = CreateObject( "CDO.Message" )
Set Stm = CreateObject( "ADODB.Stream" )
Set objShell = WScript.CreateObject("WScript.Shell")
For Each EmlFileName In WScript.Arguments
'emlファイルを開く
Stm.Open
Stm.LoadFromFile EmlFileName
Message.DataSource.OpenObject Stm, "_Stream"
'受信日時の取得と変形
strSub = Message.subject
strDtime = FormatDateTime(Message.ReceivedTime, vbShortDate)
strDtime = Replace(strDtime, "/", "")
'添付ファイルを日時と件名とファイル名を付してデスクトップに保存
For Each Attachment In Message.Attachments
SaveFile = objShell.SpecialFolders("Desktop") &_
"\\" & strDtime & "_" & strSub & "_" & Attachment.FileName
Attachment.saveToFile SaveFile
Next
Stm.Close
Next
WScript.Echo "終了"
****************ここまで*****************
PHPのsimilar_text [プログラム]
文字列の比較を検討しています。
以下の3つがありました。
・レーベンシュタイン距離
・最長共通部分列(LCS)
・PHPのsimilar_text関数
最後のが良く分からなかったので、ソースコードを追っかけてみました。
他にネット上に書かれているのは、不正確なものばかりでした。
similar_text
基本的にはこんな使い方です。
これを追っかけてみると、t1を軸にして、t2を1文字ずつずらして同じ文字列が続くかをチェックしています。
t2が終わると、t1を1文字ずらして、t2を1文字ずつすらして同じ文字列が続くかをチェックしています。
このとき、同じ文字列が続いた文字数が最大な部分を返します。
この時、最大値は同じ文字列が続いた最大値なので、その文字列が続いた後ろから開始して、他にも同じように同じ文字列が続く場所が無いかを調べます。
これを文字列が終了するまで繰り返します。
最終的には、t1と同じ文字列がどれだけ続いていたかをチェックします。
LCSと似ていますが、similar_textは、t2がt1と同じ文字列を一回チェックした後は、その値を取得できた文字列の続きから始まるため、t1とt2が入れ替わると値が異なります。
例を挙げて説明します。
t1 = "ABCBDAB";
t2 = "BDCABA";
t1のABCBDABのまま、t2をずらしてt1の頭から比較していくため、t2は4文字目のABAのときに、t1の先頭ABと合致します。
この場合、t1とt2の合致部分は、ABのみなので値は2になります。これがmaxに入ります。
t1を1バイトずらして、BCBDAB、t2は同じようにBDCABAを比較しますが、同じ文字列が最初のBのみであり連続はしませんので、値は1です。先ほどの2が大きいため、2のままです。
t1を1バイトずらして、CBDAB、t2は同じようにBDCABAを比較します。t1がCBDAB、t2がCABAの時に、最初のCが同じ文字列のため、値は1です。
t1を1バイトずらして、BDAB、t2は同じようにBDCABAを比較します。t1がBDAB、t2がBDCABAの時に、最初のBDが同じ文字列のため、値は2です。
t1を1バイトずらして、DAB、t2は同じようにBDCABAを比較します。t1がDAB、t2がDCABAの時に、最初のDが同じ文字列のため、値は1です。
t1を1バイトずらして、AB、t2は同じようにBDCABAを比較します。t1がAB、t2がABAの時に、最初のABが同じ文字列のため、値は2です。
最後は、t1がBであり、t2とBで、値が1です。
この回では、値が最大の2が返ります。
続いて、先ほどの続きから始まります。
ただし、この時、チェックが入ります。
if ((pos1 + max < len1) && (pos2 + max < len2))
これを満たさなければならないため、現在は、po1は0、po2は0、len1は7、len2は6、maxは2です。
左辺は、2 < 7、右辺は、2 < 6
であるため、満たします。
元々は
t1 = "ABCBDAB";
t2 = "BDCABA";
だったのですが、ABが共通しているため、その分を引いて
t1 = "CBDAB";
t2 = "A";
から始まります。
この場合、値は1が返ります。
先ほどの2と1を足して値は3になります。
t1とt2を逆にしてみます。
t1 = "BDCABA";
t2 = "ABCBDAB";
t1のBDCABAのまま、t2をずらしてt1の頭から比較していくため、t2は4文字目のBDABのときに、t1の先頭BDと合致します。
この場合、t1とt2の合致部分は、BDのみなので値は2になります。これがmaxに入ります。
t1を1バイトずらして、DCABA、t2は同じようにABCBDABを比較しますが、同じ文字列が最初のDのみであり連続はしませんので、値は1です。
t1を1バイトずらして、CABA、t2は同じようにABCBDABを比較します。t1がC、t2がCBDABの時に、最初のCが同じ文字列のため、値は1です。
t1を1バイトずらして、ABA、t2は同じようにABCBDABを比較します。t1がAB、t2がABの時に、ABが同じ文字列のため、値は2です。
t1を1バイトずらして、BA、t2は同じようにABCBDABを比較します。t1がAB、t2がABCBDABの時に、最初のABが同じ文字列のため、値は2です。
t1を1バイトずらして、A、t2は同じようにABCBDABを比較します。t1がA、t2がABCBDABの時に、最初のAが同じ文字列のため、値は1です。
この回では、値2が返ります。
先ほど同様、チェックが入ります。
if ((pos1 + max < len1) && (pos2 + max < len2))
現在は、po1は0、po2は0、len1は6、len2は7、maxは2です。
左辺は、2 < 6、右辺は、2 < 7
であるため、満たします。
続いて、先ほどの続きから始まります。
元々は、
t1 = "BDCABA";
t2 = "ABCBDAB";
だったのですが、BDが共通しているため、その分を引いて
t1 = "CABA";
t2 = "AB";
から始まります。
この場合、ABが共通しているので、値は2が返ります。
先ほどの2と2を足して値は4になります。
以上から、
t1 = "ABCBDAB";
t2 = "BDCABA";
では、値は3でした。
t1 = "BDCABA";
t2 = "ABCBDAB";
では、値が4でした。
このように入れ替えると答えが異なります。
以下の3つがありました。
・レーベンシュタイン距離
・最長共通部分列(LCS)
・PHPのsimilar_text関数
最後のが良く分からなかったので、ソースコードを追っかけてみました。
他にネット上に書かれているのは、不正確なものばかりでした。
similar_text
static void php_similar_str(const char *txt1, int len1, const char *txt2, int len2, int *pos1, int *pos2, int *max)
{
char *p, *q;
char *end1 = (char *)txt1 + len1;
char *end2 = (char *)txt2 + len2;
int l;
*max = 0;
for (p = (char *)txt1; p < end1; p++) {
for (q = (char *)txt2; q < end2; q++) {
for (l = 0; (p + l < end1) && (q + l < end2) && (p[l] == q[l]); l++);
if (l > *max) {
*max = l;
*pos1 = p - txt1;
*pos2 = q - txt2;
}
}
}
}
static int php_similar_char(const char *txt1, int len1, const char *txt2, int len2)
{
int sum;
int pos1 = 0, pos2 = 0, max;
php_similar_str(txt1, len1, txt2, len2, &pos1, &pos2, &max);
if ((sum = max)) {
if (pos1 && pos2) {
sum += php_similar_char(txt1, pos1,
txt2, pos2);
}
if ((pos1 + max < len1) && (pos2 + max < len2)) {
sum += php_similar_char(txt1 + pos1 + max, len1 - pos1 - max,
txt2 + pos2 + max, len2 - pos2 - max);
}
}
return sum;
}
基本的にはこんな使い方です。
char *t1, *t2; int sim; int t1_len, t2_len; float per = 0; t1 = "ABCBDAB"; t2 = "BDCABA"; t1_len = strlen(t1); t2_len = strlen(t2); sim = php_similar_char(t1, t1_len, t2, t2_len); per = sim * 200.0 / (t1_len + t2_len);
これを追っかけてみると、t1を軸にして、t2を1文字ずつずらして同じ文字列が続くかをチェックしています。
t2が終わると、t1を1文字ずらして、t2を1文字ずつすらして同じ文字列が続くかをチェックしています。
このとき、同じ文字列が続いた文字数が最大な部分を返します。
この時、最大値は同じ文字列が続いた最大値なので、その文字列が続いた後ろから開始して、他にも同じように同じ文字列が続く場所が無いかを調べます。
これを文字列が終了するまで繰り返します。
最終的には、t1と同じ文字列がどれだけ続いていたかをチェックします。
LCSと似ていますが、similar_textは、t2がt1と同じ文字列を一回チェックした後は、その値を取得できた文字列の続きから始まるため、t1とt2が入れ替わると値が異なります。
例を挙げて説明します。
t1 = "ABCBDAB";
t2 = "BDCABA";
t1のABCBDABのまま、t2をずらしてt1の頭から比較していくため、t2は4文字目のABAのときに、t1の先頭ABと合致します。
この場合、t1とt2の合致部分は、ABのみなので値は2になります。これがmaxに入ります。
t1を1バイトずらして、BCBDAB、t2は同じようにBDCABAを比較しますが、同じ文字列が最初のBのみであり連続はしませんので、値は1です。先ほどの2が大きいため、2のままです。
t1を1バイトずらして、CBDAB、t2は同じようにBDCABAを比較します。t1がCBDAB、t2がCABAの時に、最初のCが同じ文字列のため、値は1です。
t1を1バイトずらして、BDAB、t2は同じようにBDCABAを比較します。t1がBDAB、t2がBDCABAの時に、最初のBDが同じ文字列のため、値は2です。
t1を1バイトずらして、DAB、t2は同じようにBDCABAを比較します。t1がDAB、t2がDCABAの時に、最初のDが同じ文字列のため、値は1です。
t1を1バイトずらして、AB、t2は同じようにBDCABAを比較します。t1がAB、t2がABAの時に、最初のABが同じ文字列のため、値は2です。
最後は、t1がBであり、t2とBで、値が1です。
この回では、値が最大の2が返ります。
続いて、先ほどの続きから始まります。
ただし、この時、チェックが入ります。
if ((pos1 + max < len1) && (pos2 + max < len2))
これを満たさなければならないため、現在は、po1は0、po2は0、len1は7、len2は6、maxは2です。
左辺は、2 < 7、右辺は、2 < 6
であるため、満たします。
元々は
t1 = "ABCBDAB";
t2 = "BDCABA";
だったのですが、ABが共通しているため、その分を引いて
t1 = "CBDAB";
t2 = "A";
から始まります。
この場合、値は1が返ります。
先ほどの2と1を足して値は3になります。
t1とt2を逆にしてみます。
t1 = "BDCABA";
t2 = "ABCBDAB";
t1のBDCABAのまま、t2をずらしてt1の頭から比較していくため、t2は4文字目のBDABのときに、t1の先頭BDと合致します。
この場合、t1とt2の合致部分は、BDのみなので値は2になります。これがmaxに入ります。
t1を1バイトずらして、DCABA、t2は同じようにABCBDABを比較しますが、同じ文字列が最初のDのみであり連続はしませんので、値は1です。
t1を1バイトずらして、CABA、t2は同じようにABCBDABを比較します。t1がC、t2がCBDABの時に、最初のCが同じ文字列のため、値は1です。
t1を1バイトずらして、ABA、t2は同じようにABCBDABを比較します。t1がAB、t2がABの時に、ABが同じ文字列のため、値は2です。
t1を1バイトずらして、BA、t2は同じようにABCBDABを比較します。t1がAB、t2がABCBDABの時に、最初のABが同じ文字列のため、値は2です。
t1を1バイトずらして、A、t2は同じようにABCBDABを比較します。t1がA、t2がABCBDABの時に、最初のAが同じ文字列のため、値は1です。
この回では、値2が返ります。
先ほど同様、チェックが入ります。
if ((pos1 + max < len1) && (pos2 + max < len2))
現在は、po1は0、po2は0、len1は6、len2は7、maxは2です。
左辺は、2 < 6、右辺は、2 < 7
であるため、満たします。
続いて、先ほどの続きから始まります。
元々は、
t1 = "BDCABA";
t2 = "ABCBDAB";
だったのですが、BDが共通しているため、その分を引いて
t1 = "CABA";
t2 = "AB";
から始まります。
この場合、ABが共通しているので、値は2が返ります。
先ほどの2と2を足して値は4になります。
以上から、
t1 = "ABCBDAB";
t2 = "BDCABA";
では、値は3でした。
t1 = "BDCABA";
t2 = "ABCBDAB";
では、値が4でした。
このように入れ替えると答えが異なります。
PHPでUnixtime変換 [プログラム]
ずっと昔にPerlでUnixtime変換を書いていました。
http://jemsec.blog.so-net.ne.jp/2005-07-04
なので、PHPで書いてみました。
Unixtimeを時刻に変換
>php -r "echo date('Y/m/d H:i:s', 1394203709) . PHP_EOL;"
2014/03/07 23:48:29
文字列をUnixtimeに変換
>php -r "echo strtotime('2014/03/07 23:50:00') . PHP_EOL;"
1394203800
http://jemsec.blog.so-net.ne.jp/2005-07-04
なので、PHPで書いてみました。
Unixtimeを時刻に変換
>php -r "echo date('Y/m/d H:i:s', 1394203709) . PHP_EOL;"
2014/03/07 23:48:29
文字列をUnixtimeに変換
>php -r "echo strtotime('2014/03/07 23:50:00') . PHP_EOL;"
1394203800
pythonとdpktでパケット解析 [プログラム]
pythonでpcapファイルを解析する方法
dpktモジュールを使えば簡単にできました。
使い方
#python pcap.py [pcapファイル]
dpktモジュールを使えば簡単にできました。
使い方
#python pcap.py [pcapファイル]
ファイル名
pcap.py
# -*- coding: utf-8 -*-
import dpkt, socket
import string
import binascii
import sys
#メイン関数
def main(filename):
pcr = dpkt.pcap.Reader(open(filename,'rb'))
#パケット数
packet_count = 0
#パケット処理
for ts,buf in pcr:
packet_count += 1
try:
eth = dpkt.ethernet.Ethernet(buf)
except:
continue
#IPデータの場合
if type(eth.data) == dpkt.ip.IP:
ip = eth.data
ipheader(ip)
#TCPデータ
if type(ip.data) == dpkt.tcp.TCP:
tcp = ip.data
#ペイロードが0以外
if len(tcp.data) != 0:
thex = binascii.b2a_hex(tcp.data)
payload(thex)
#UDPデータ
elif type(ip.data) == dpkt.udp.UDP:
udp = ip.data
#ペイロードが0以外
if len(udp.data) != 0:
uhex = binascii.b2a_hex(udp.data)
payload(uhex)
#ICMPデータ
elif type(ip.data) == dpkt.icmp.ICMP:
icmp = ip.data
#ペイロードが0以外
if len(icmp.data) != 0:
ihex = binascii.hexlify(str(icmp.data))
payload(ihex[8:])
print "処理終了:", packet_count
#IPヘッダ処理
def ipheader(header):
#ヘッダの処理
src = socket.inet_ntoa(header.src)
dst = socket.inet_ntoa(header.dst)
#TCP
if type(header.data) == dpkt.tcp.TCP:
print "TCP %s:%s => %s:%s (len:%s)" % (src, header.data.sport, dst, header.data.dport, len(header.data.data))
#UDP
elif type(header.data) == dpkt.udp.UDP:
print "UDP %s:%s => %s:%s (len:%s)" % (src, header.data.sport, dst, header.data.dport, len(header.data.data))
#ICMP
elif type(header.data) == dpkt.icmp.ICMP:
print "ICMP %s:type %s,code %s => %s (len:%s)" % (src, header.data.type, header.data.code, dst, len(header.data.data))
#その他
else:
print "%s => %s" % (src, dst)
#ペイロード
def payload(thex):
#ペイロードの処理
return
#メイン関数
if __name__ == '__main__':
if (len(sys.argv) != 2):
print "ファイルを指定して下さい"
exit()
#第2引数をファイル名にする
filename = sys.argv[1]
main(filename)
emlファイルから添付ファイルを抽出するスクリプト2 [プログラム]
昨日作ったのを改良しました。
複数のファイルをドラッグ&ドロップしても大丈夫です。
emlファイルから添付ファイルを抽出するスクリプト
当該スクリプトをvbsファイルに保存し、複数のemlファイルをドラッグ&ドロップでデスクトップに添付ファイルが保存されます。
添付ファイルは受信日時と添付ファイル名がくっつくようにしています。
*********ここから***************
****************ここまで*****************
複数のファイルをドラッグ&ドロップしても大丈夫です。
emlファイルから添付ファイルを抽出するスクリプト
当該スクリプトをvbsファイルに保存し、複数のemlファイルをドラッグ&ドロップでデスクトップに添付ファイルが保存されます。
添付ファイルは受信日時と添付ファイル名がくっつくようにしています。
*********ここから***************
Option Explicit
Dim EmlFileName
Dim Message,Stm,Attachment,Dtime,strDtime
Dim SaveFile,objShell
Set Message = CreateObject( "CDO.Message" )
Set Stm = CreateObject( "ADODB.Stream" )
Set objShell = WScript.CreateObject("WScript.Shell")
For Each EmlFileName In WScript.Arguments
'emlファイルを開く
Stm.Open
Stm.LoadFromFile EmlFileName
Message.DataSource.OpenObject Stm, "_Stream"
'受信日時の取得と変形
Dtime = Message.ReceivedTime
strDtime = FormatDateTime(Message.ReceivedTime, vbShortDate)
strDtime = Replace(strDtime, "/", "")
'添付ファイルを日時とファイル名を付してデスクトップに保存
For Each Attachment In Message.Attachments
SaveFile = objShell.SpecialFolders("Desktop") &_
"\\" & strDtime & "_" & Attachment.FileName
Attachment.saveToFile SaveFile
Next
Stm.Close
Next
WScript.Echo "終了"
****************ここまで*****************
emlファイルから添付ファイルを抽出するスクリプト [プログラム]
emlファイルから添付ファイルを抽出するスクリプト
当該スクリプトをvbsファイルに保存し、emlファイルをドラッグ&ドロップでデスクトップに添付ファイルが保存されます。
添付ファイルは受信日時と添付ファイル名がくっつくようにしています。
*********ここから***************
****************ここまで*****************
当該スクリプトをvbsファイルに保存し、emlファイルをドラッグ&ドロップでデスクトップに添付ファイルが保存されます。
添付ファイルは受信日時と添付ファイル名がくっつくようにしています。
*********ここから***************
Dim EmlFileName
Dim Message,Stm,Attachment,Dtime,strDtime
Dim SaveFile,objShell
'第一引数をemlファイルとして読込
EmlFileName = WScript.Arguments(0)
Set Message = CreateObject("CDO.Message")
Set Stm = CreateObject("ADODB.Stream")
Set objShell = WScript.CreateObject("WScript.Shell")
'emlファイルを開く
Stm.Open
Stm.LoadFromFile EmlFileName
Message.DataSource.OpenObject Stm, "_Stream"
'受信日時の取得と変形
Dtime = Message.ReceivedTime
strDtime = FormatDateTime(Message.ReceivedTime, vbShortDate)
strDtime = Replace(strDtime, "/", "")
'添付ファイルを日時とファイル名を付してデスクトップに保存
For Each Attachment In Message.Attachments
SaveFile = objShell.SpecialFolders("Desktop") &_
"\\" & strDtime & "_" & Attachment.FileName
Attachment.saveToFile SaveFile
Next
Stm.Close
****************ここまで*****************
Remnux [プログラム]
時刻
$sudo cp /etc/localtime /etc/localtime.bak
$sudo cp /user/share/zoneinfo/Asia/Tokyo /etc/localtime
キーボード
setxkbmap jp
これを.bashrcに追加すれば日本語キーボードがロ グイン時に使える。 ターミナルで打てばすぐに反映される。
http://zeltser.com/remnux/
$sudo cp /etc/localtime /etc/localtime.bak
$sudo cp /user/share/zoneinfo/Asia/Tokyo /etc/localtime
キーボード
setxkbmap jp
これを.bashrcに追加すれば日本語キーボードがロ グイン時に使える。 ターミナルで打てばすぐに反映される。
http://zeltser.com/remnux/
Smarty-3.1.3のバグ? [プログラム]
Smartyが3.1.3になったのでアップデートしてみたら、Noticeエラーが表示。
Notice: Uninitialized string offset: 1 in Smarty-3.1.3/libs/plugins/function.html_select_date.php on line 355
私が以前は、Smarty-3.0.7だったため、どのバージョンからこのように変わったかは不明。
Smarty-3.1.3/libs/plugins/function.html_select_date.phpのソースを見ると
どうやら3桁を想定して処理されているようだ。
ま、あまりよろしくない仕様ですかね。
defaultケースの場合が記載されていないし。
354行目の
354 for ($i=0; $i <= 2; $i++) {
を
354 for ($i=0; $i <= count($field_order); $i++) {
に修正で直るはずですが、申請すればいいんだろうか?
これの何が問題かというと、今まで日本語の
2011年10月10日
のように表示するために、一つずつ、
{Smarty表記}年{Smarty表記}月{Smarty表記}日
としていたため、
field_orderは
field_order = "Y"
と1桁で表記していた。
詳細はこのページを参照してください。
http://techblog.crooz.jp/?p=4210
しかし、上記のソースに変わったため、これは使えない。
ということで、元を修正するのは、今後のバージョンアップに反映してくれないと意味がないため、開発者側で3桁にすればいいのだから、
field_order = "Y--"
field_order = "M--"
field_order = "d--"
とすることで解決。
「--」は、「YyMmDd」以外なら3桁にするため何の文字でもOK。
Smartyの時刻表示はYMDとセパレータ「/など」のみでの表示のため、すぐには改善してくれないかも。
Smartyは、
2011/10/10
や
2011-10-10
を想定していると思うので。
Notice: Uninitialized string offset: 1 in Smarty-3.1.3/libs/plugins/function.html_select_date.php on line 355
私が以前は、Smarty-3.0.7だったため、どのバージョンからこのように変わったかは不明。
Smarty-3.1.3/libs/plugins/function.html_select_date.phpのソースを見ると
354 for ($i=0; $i <= 2; $i++) {
355 switch ($field_order[$i]) {
356 case 'Y':
357 case 'y':
358 if (isset($_html_years)) {
359 if ($_html) {
360 $_html .= $field_separator;
361 }
362 $_html .= $_html_years;
363 }
364 break;
どうやら3桁を想定して処理されているようだ。
ま、あまりよろしくない仕様ですかね。
defaultケースの場合が記載されていないし。
354行目の
354 for ($i=0; $i <= 2; $i++) {
を
354 for ($i=0; $i <= count($field_order); $i++) {
に修正で直るはずですが、申請すればいいんだろうか?
これの何が問題かというと、今まで日本語の
2011年10月10日
のように表示するために、一つずつ、
{Smarty表記}年{Smarty表記}月{Smarty表記}日
としていたため、
field_orderは
field_order = "Y"
と1桁で表記していた。
詳細はこのページを参照してください。
http://techblog.crooz.jp/?p=4210
しかし、上記のソースに変わったため、これは使えない。
ということで、元を修正するのは、今後のバージョンアップに反映してくれないと意味がないため、開発者側で3桁にすればいいのだから、
field_order = "Y--"
field_order = "M--"
field_order = "d--"
とすることで解決。
「--」は、「YyMmDd」以外なら3桁にするため何の文字でもOK。
Smartyの時刻表示はYMDとセパレータ「/など」のみでの表示のため、すぐには改善してくれないかも。
Smartyは、
2011/10/10
や
2011-10-10
を想定していると思うので。
zabbixのAPIを使用したデータの取得のPHP [プログラム]
zabbix APIを使用してデータを取得する場合のPHP処理。
authとURLのところは変更して下さい。
authはこれを実行する前に一度認証処理を行って、返ってきた値です。
itemidsは取得したい値のIDです。
time_fromは指定した時刻以降のデータを取得します。
Zabbix-API用のユーザに特権管理者権限を付与して下さい。
<?php
//cURL初期化
$channel = curl_init();
//パラメータ設定
$options = array(
//リダイレクトする前のURLをセット
CURLOPT_AUTOREFERER => TRUE,
//HTTP で 400 以上のコードが返ってきた際に 処理失敗と判断し、何もしない
CURLOPT_FAILONERROR => FALSE,
//戻り値を文字列として扱う
CURLOPT_RETURNTRANSFER => TRUE,
//POST
CURLOPT_POST => TRUE,
CURLOPT_POSTFIELDS => '{"auth":"aaabbbcccddd11122233344455566fff","method":"history.get",
"id":1,"params":{"itemids":["10"],"time_from":"1316058010",
"output":"extend"},"jsonrpc":"2.0"}',
//Header
CURLOPT_HTTPHEADER => array('Content-Type: application/json-rpc'),
//URL
CURLOPT_URL => 'http://192.168.0.1/zabbix/api_jsonrpc.php',
//ユーザエージェント
CURLOPT_USERAGENT => 'Mozilla/4.0',
);
//オプション設定の追加
curl_setopt_array($channel, $options);
//cURLを実行
$body = curl_exec($channel);
$response_data['body'] = $body;
//URL IDのデータを配列に追加
//閉じる
curl_close($channel);
unset($channel);
$result_buf = json_decode($response_data['body'], true);
$result = array();
foreach($result_buf['result'] as $value)
{
$clock = date('Y/m/d H:i:s', $value['clock']);
$result[$clock] = $value['value'];
}
var_dump($result);
?>
![[わーい(嬉しい顔)]](https://blog.ss-blog.jp/_images_e/140.gif)
これの結果
array(7) {
["2011/09/15 12:40:10"]=>
string(2) "61"
["2011/09/15 12:50:10"]=>
string(2) "61"
["2011/09/15 13:00:10"]=>
string(2) "61"
["2011/09/15 13:10:10"]=>
string(2) "61"
["2011/09/15 13:20:10"]=>
string(2) "61"
["2011/09/15 13:30:10"]=>
string(2) "61"
["2011/09/15 13:40:10"]=>
string(2) "61"
}
authとURLのところは変更して下さい。
authはこれを実行する前に一度認証処理を行って、返ってきた値です。
itemidsは取得したい値のIDです。
time_fromは指定した時刻以降のデータを取得します。
Zabbix-API用のユーザに特権管理者権限を付与して下さい。
<?php
//cURL初期化
$channel = curl_init();
//パラメータ設定
$options = array(
//リダイレクトする前のURLをセット
CURLOPT_AUTOREFERER => TRUE,
//HTTP で 400 以上のコードが返ってきた際に 処理失敗と判断し、何もしない
CURLOPT_FAILONERROR => FALSE,
//戻り値を文字列として扱う
CURLOPT_RETURNTRANSFER => TRUE,
//POST
CURLOPT_POST => TRUE,
CURLOPT_POSTFIELDS => '{"auth":"aaabbbcccddd11122233344455566fff","method":"history.get",
"id":1,"params":{"itemids":["10"],"time_from":"1316058010",
"output":"extend"},"jsonrpc":"2.0"}',
//Header
CURLOPT_HTTPHEADER => array('Content-Type: application/json-rpc'),
//URL
CURLOPT_URL => 'http://192.168.0.1/zabbix/api_jsonrpc.php',
//ユーザエージェント
CURLOPT_USERAGENT => 'Mozilla/4.0',
);
//オプション設定の追加
curl_setopt_array($channel, $options);
//cURLを実行
$body = curl_exec($channel);
$response_data['body'] = $body;
//URL IDのデータを配列に追加
//閉じる
curl_close($channel);
unset($channel);
$result_buf = json_decode($response_data['body'], true);
$result = array();
foreach($result_buf['result'] as $value)
{
$clock = date('Y/m/d H:i:s', $value['clock']);
$result[$clock] = $value['value'];
}
var_dump($result);
?>
これの結果
array(7) {
["2011/09/15 12:40:10"]=>
string(2) "61"
["2011/09/15 12:50:10"]=>
string(2) "61"
["2011/09/15 13:00:10"]=>
string(2) "61"
["2011/09/15 13:10:10"]=>
string(2) "61"
["2011/09/15 13:20:10"]=>
string(2) "61"
["2011/09/15 13:30:10"]=>
string(2) "61"
["2011/09/15 13:40:10"]=>
string(2) "61"
}
MySQLのレコード数 [プログラム]
MySQLの場合のテーブルのレコード数
SELECT table_name, table_rows FROM information_schema.TABLES;
データベース名で絞るなら、
WHERE table_schema = 'データベース名'
を最後に追加。
テーブル名で絞るなら、
WHERE table_schema = 'データベース名' AND table_name = 'テーブル名'
を最後に追加。
SELECT table_name, table_rows FROM information_schema.TABLES;
データベース名で絞るなら、
WHERE table_schema = 'データベース名'
を最後に追加。
テーブル名で絞るなら、
WHERE table_schema = 'データベース名' AND table_name = 'テーブル名'
を最後に追加。
SQLiteのレコード数 [プログラム]
SQLiteのレコード数を知るいい方法がないかなぁ。
通常、SQL文で、
SELECT COUNT(*) from table;
とかでレコード件数が出力されますが、120万件とかあると10秒~20秒ぐらい掛かってしまう時があります。
インデックスも付与しているのだから、さくっと、結果が表示される方法がないかなぁ。
OracleとかMySQLみたいに統計情報を持っていればさくっと出るのでしょうけど。
通常、SQL文で、
SELECT COUNT(*) from table;
とかでレコード件数が出力されますが、120万件とかあると10秒~20秒ぐらい掛かってしまう時があります。
インデックスも付与しているのだから、さくっと、結果が表示される方法がないかなぁ。
OracleとかMySQLみたいに統計情報を持っていればさくっと出るのでしょうけど。
mysqlコマンドTips [プログラム]
MySQLのコマンド
1行でMySQLのコマンドを記述。
これでスクリプトも実行可能
rootのパスワードを1234とします。
テーブル名をtest_tbとします。
#mysql -u root -p1234 -e "SQL文"
例えば、テーブルのステータス表示。
#mysql -u root -p1234 -e "show table status from test_db \G"
最後の\Gは、コマンドラインで改行がなく見にくい場合、1行ごとに縦に表示してくれます。
全体のステータス表示。
# mysql -u root -p1234 -e "show status"
表示例
(略)
| Rpl_status | NULL |
| Select_full_join | 0 |
| Select_full_range_join | 0 |
| Select_range | 0 |
| Select_range_check | 0 |
| Select_scan | 0 |
| Slave_open_temp_tables | 0 |
| Slave_retried_transactions | 0 |
| Slave_running | OFF |
| Slow_launch_threads | 0 |
| Slow_queries | 0 |
| Sort_merge_passes | 0 |
| Sort_range | 0 |
| Sort_rows | 0 |
| Sort_scan | 0 |
(略)
MySQLのステータス表示。
#mysql -u root -p1234 -e "status"
表示例
(略)
Connection id: 2773
Current database:
Current user: root@localhost
SSL: Not in use
Current pager: stdout
Using outfile: ''
Using delimiter: ;
Server version: 5.1.54 MySQL Community Server (GPL) by Remi
Protocol version: 10
Connection: Localhost via UNIX socket
Server characterset: utf8
Db characterset: utf8
Client characterset: latin1
Conn. characterset: latin1
UNIX socket: /var/lib/mysql/mysql.sock
Uptime: 27 min 42 sec
Threads: 23 Questions: 13280 Slow queries: 9 Opens: 113 Flush tables: 1 Open tables: 64 Queries per second avg: 7.990
また、コメントなどの日本語を使用している場合は文字化けするので、以下のようにします。
#mysql -u root -p1234 -e "set names utf8;show table status from test_db \G"
表示例
(略)
*************************** 7. row ***************************
Name: web_test
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 4537197
Avg_row_length: 68
Data_length: 311885824
Max_data_length: 0
Index_length: 480378880
Data_free: 5400166400
Auto_increment: 13823510
Create_time: NULL
Update_time: NULL
Check_time: NULL
Collation: utf8_unicode_ci
Checksum: NULL
Create_options: partitioned
Comment: データを格納
(略)
現在実行中のSQLリスト
#mysql -u root -p1234 -e "show full processlist \G"
表示例
*************************** 24. row ***************************
Id: 2266
User: root
Host: localhost
db: NULL
Command: Query
Time: 0
State: NULL
Info: show full processlist
実行中のSQL IDの123を強制終了させる場合
mysql -u root -pnonamasu -e "kill 123"
1行でMySQLのコマンドを記述。
これでスクリプトも実行可能
rootのパスワードを1234とします。
テーブル名をtest_tbとします。
#mysql -u root -p1234 -e "SQL文"
例えば、テーブルのステータス表示。
#mysql -u root -p1234 -e "show table status from test_db \G"
最後の\Gは、コマンドラインで改行がなく見にくい場合、1行ごとに縦に表示してくれます。
全体のステータス表示。
# mysql -u root -p1234 -e "show status"
表示例
(略)
| Rpl_status | NULL |
| Select_full_join | 0 |
| Select_full_range_join | 0 |
| Select_range | 0 |
| Select_range_check | 0 |
| Select_scan | 0 |
| Slave_open_temp_tables | 0 |
| Slave_retried_transactions | 0 |
| Slave_running | OFF |
| Slow_launch_threads | 0 |
| Slow_queries | 0 |
| Sort_merge_passes | 0 |
| Sort_range | 0 |
| Sort_rows | 0 |
| Sort_scan | 0 |
(略)
MySQLのステータス表示。
#mysql -u root -p1234 -e "status"
表示例
(略)
Connection id: 2773
Current database:
Current user: root@localhost
SSL: Not in use
Current pager: stdout
Using outfile: ''
Using delimiter: ;
Server version: 5.1.54 MySQL Community Server (GPL) by Remi
Protocol version: 10
Connection: Localhost via UNIX socket
Server characterset: utf8
Db characterset: utf8
Client characterset: latin1
Conn. characterset: latin1
UNIX socket: /var/lib/mysql/mysql.sock
Uptime: 27 min 42 sec
Threads: 23 Questions: 13280 Slow queries: 9 Opens: 113 Flush tables: 1 Open tables: 64 Queries per second avg: 7.990
また、コメントなどの日本語を使用している場合は文字化けするので、以下のようにします。
#mysql -u root -p1234 -e "set names utf8;show table status from test_db \G"
表示例
(略)
*************************** 7. row ***************************
Name: web_test
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 4537197
Avg_row_length: 68
Data_length: 311885824
Max_data_length: 0
Index_length: 480378880
Data_free: 5400166400
Auto_increment: 13823510
Create_time: NULL
Update_time: NULL
Check_time: NULL
Collation: utf8_unicode_ci
Checksum: NULL
Create_options: partitioned
Comment: データを格納
(略)
現在実行中のSQLリスト
#mysql -u root -p1234 -e "show full processlist \G"
表示例
*************************** 24. row ***************************
Id: 2266
User: root
Host: localhost
db: NULL
Command: Query
Time: 0
State: NULL
Info: show full processlist
実行中のSQL IDの123を強制終了させる場合
mysql -u root -pnonamasu -e "kill 123"
zabbixのアイテムにおける計算(詳細) [プログラム]
zabbixのアイテムには新たに計算というのがあります。
これは結構情報が少ないので、詳細に書いておきます。
SNMPではCPUのIdleというのが取れるので、これを100から引く方法でCPUの使用率を計算する方法を紹介します。
厳密には、niceやuser、systemの占有カウンタ値を前回の値からの差分で取得して、割合を計算するのですが、面倒なのでIdleから引くのが簡単です。
まずはアイテムの登録。CPUのIdleを登録します。
ホスト:登録したホストを選択。
説明:日本語でも何でもOK。
タイプ:SNMPv1エージェントを選択。SNMPv3でも設定しているバージョンで。
SNMP OID:いわゆるMIB値やエイリアスを。ここでは、UCD-SNMP-MIB::ssCpuIdle.0(CPUのコア1個目)を取得しています。
SNMPコミュニティ:SNMPのコミュニティ値を。privateやpublicが一般的かと思います。
SNMPポート:SNMPのポートはデフォルトは161です。
キー:全体を通したユニークな値を記載。判別するためのものであり何でも良いです。計算の時にこの文字列を使います。多分アルファベットが無難。ここではssCpuIdle.0を記述。
データ型:数値(整数)
データの形式:10進数
単位:%
乗数を使用:チェックなし
更新間隔(秒):好きな間隔。デフォルトは30。
例外の更新間隔(秒):例外の更新間隔はありません
例外の更新間隔の作成:例外設定。
ヒストリの保存期間(日):データの保存期間。デフォルトは90日間です。
トレンドの保存期間(日):グラフの保存期間。データよりおおざっぱになります。デフォルトは365日。
ステータス:有効
保存時の計算:なし
値のマッピングの使用:なし
アプリケーションの作成:なし
アプリケーション:好きな設定で。cpuは、アプリケーションの作成で作成した者です。
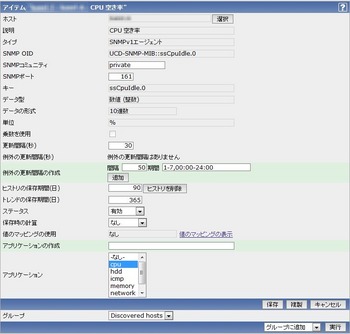
続いて、計算を登録します。
ホスト:登録したホストを選択。
説明:日本語でも何でもOK。
タイプ:計算を選択。
キー:何でもいい。分かりやすいユニーク値。
式:100-last("ssCpuIdle.0") これで100からさきほど登録したCPUのIdle値を引きます。lastは直近の値。
データ型:数値(整数)
データの形式:10進数
単位:%
乗数を使用:チェックしない。
更新間隔(秒):30秒。
例外の更新間隔(秒):例外の更新間隔はありません
例外の更新間隔の作成:そのまま。
ヒストリの保存期間(日):90日
トレンドの保存期間(日):365日
ステータス:有効
保存時の計算:なし
値のマッピングの使用:なし
アプリケーションの作成:なし
アプリケーション:cpu。さきほどのアイテムと同じ。
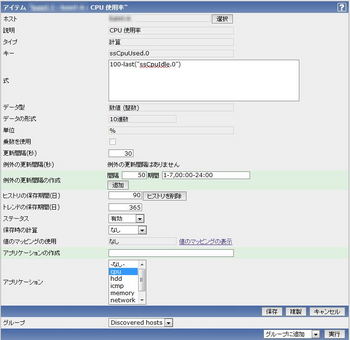
これで、まず、CPUのアイドル値を取得し、その後に計算をしてデータを保存します。
多分、両方の値が保存されるような気がするので(未確認)、その分データ量は増えると思います。
これは結構情報が少ないので、詳細に書いておきます。
SNMPではCPUのIdleというのが取れるので、これを100から引く方法でCPUの使用率を計算する方法を紹介します。
厳密には、niceやuser、systemの占有カウンタ値を前回の値からの差分で取得して、割合を計算するのですが、面倒なのでIdleから引くのが簡単です。
まずはアイテムの登録。CPUのIdleを登録します。
ホスト:登録したホストを選択。
説明:日本語でも何でもOK。
タイプ:SNMPv1エージェントを選択。SNMPv3でも設定しているバージョンで。
SNMP OID:いわゆるMIB値やエイリアスを。ここでは、UCD-SNMP-MIB::ssCpuIdle.0(CPUのコア1個目)を取得しています。
SNMPコミュニティ:SNMPのコミュニティ値を。privateやpublicが一般的かと思います。
SNMPポート:SNMPのポートはデフォルトは161です。
キー:全体を通したユニークな値を記載。判別するためのものであり何でも良いです。計算の時にこの文字列を使います。多分アルファベットが無難。ここではssCpuIdle.0を記述。
データ型:数値(整数)
データの形式:10進数
単位:%
乗数を使用:チェックなし
更新間隔(秒):好きな間隔。デフォルトは30。
例外の更新間隔(秒):例外の更新間隔はありません
例外の更新間隔の作成:例外設定。
ヒストリの保存期間(日):データの保存期間。デフォルトは90日間です。
トレンドの保存期間(日):グラフの保存期間。データよりおおざっぱになります。デフォルトは365日。
ステータス:有効
保存時の計算:なし
値のマッピングの使用:なし
アプリケーションの作成:なし
アプリケーション:好きな設定で。cpuは、アプリケーションの作成で作成した者です。

続いて、計算を登録します。
ホスト:登録したホストを選択。
説明:日本語でも何でもOK。
タイプ:計算を選択。
キー:何でもいい。分かりやすいユニーク値。
式:100-last("ssCpuIdle.0") これで100からさきほど登録したCPUのIdle値を引きます。lastは直近の値。
データ型:数値(整数)
データの形式:10進数
単位:%
乗数を使用:チェックしない。
更新間隔(秒):30秒。
例外の更新間隔(秒):例外の更新間隔はありません
例外の更新間隔の作成:そのまま。
ヒストリの保存期間(日):90日
トレンドの保存期間(日):365日
ステータス:有効
保存時の計算:なし
値のマッピングの使用:なし
アプリケーションの作成:なし
アプリケーション:cpu。さきほどのアイテムと同じ。

これで、まず、CPUのアイドル値を取得し、その後に計算をしてデータを保存します。
多分、両方の値が保存されるような気がするので(未確認)、その分データ量は増えると思います。
ollydbgで書き換えた後、保存する方法 [プログラム]
ollydbgで書き換えた後、実行ファイルを保存する方法のメモ。
EXEをollydbgで開く。
命令部分などを書き換える。
CPUメイン画面上で、右クリック→[Copy to executable]→[All modifications]をクリック。
ウィンドウが出てくるので、[Copy all]をクリック。
Fileウィンドウにコピーされた内容が表示される。
#そのウィンドウ上で右クリック、[Special]→[PE header]をクリックすれば、PEヘッダの詳細が分かるように解説される。
Fileウィンドウで右クリック→[Save file]で保存先を選んで保存する。
#このとき、元のファイル名とは異なるファイル名にする。
遠い昔、あるソフトウェアをollydbgで解析して、バイナリを書き換えて、××して○○したから△△したなぁ。
EXEをollydbgで開く。
命令部分などを書き換える。
CPUメイン画面上で、右クリック→[Copy to executable]→[All modifications]をクリック。
ウィンドウが出てくるので、[Copy all]をクリック。
Fileウィンドウにコピーされた内容が表示される。
#そのウィンドウ上で右クリック、[Special]→[PE header]をクリックすれば、PEヘッダの詳細が分かるように解説される。
Fileウィンドウで右クリック→[Save file]で保存先を選んで保存する。
#このとき、元のファイル名とは異なるファイル名にする。
遠い昔、あるソフトウェアをollydbgで解析して、バイナリを書き換えて、××して○○したから△△したなぁ。
Smarty3が登場 [プログラム]
Smarty 3.0.5が出てました。
というか知らない間にSmarty 3.0が登場していました。
さっそく入れてみたら、エラーが発生。
__autoload関数が呼ばれない。
色々調べてみたら、__autoload関数を使用する場合は、スタック登録が必要だそうな。
spl_autoload_register('__autoload');とやれば動作しました。
スタック登録するので、__autoload関数という名称でなくてもよさそうな気がします。
というか知らない間にSmarty 3.0が登場していました。
さっそく入れてみたら、エラーが発生。
__autoload関数が呼ばれない。
色々調べてみたら、__autoload関数を使用する場合は、スタック登録が必要だそうな。
spl_autoload_register('__autoload');とやれば動作しました。
スタック登録するので、__autoload関数という名称でなくてもよさそうな気がします。
JavaScriptPacker [プログラム]
JavaScriptPackerという、JavaScriptを難読化するライブラリがあるようです。
JavaScriptPacker
難読化をしてせっかく苦労して作ったものを人に真似されるのを防ぐためなんでしょうけど、巷でいまだに流行っている「Gumblar」はJavaScriptの難読化によってウィルス対策ソフトをすり抜けようとしているので、悪用されている気がします。
このライブラリは、常にevalで表示させようとするので、「Gumblar」とはまったく同じではありませんが、似たような技術が使われているんじゃないかなぁ。
JavaScriptPacker
難読化をしてせっかく苦労して作ったものを人に真似されるのを防ぐためなんでしょうけど、巷でいまだに流行っている「Gumblar」はJavaScriptの難読化によってウィルス対策ソフトをすり抜けようとしているので、悪用されている気がします。
このライブラリは、常にevalで表示させようとするので、「Gumblar」とはまったく同じではありませんが、似たような技術が使われているんじゃないかなぁ。
PHPでHTMLの数値文字参照を変換するメソッド [プログラム]
PHPでHTMLの数値文字参照を変換するメソッドを作成しました。
10進数でも16進数でも強制的に変換してくれるはずです。
phpdoc風
/**
* 数値文字参照変換メソッド
*
* 10進数、16進数の数値文字参照を文字列に変換する。
*
* @param string line 変換前の文字列
* @param string enc 変換する文字コード 指定しなければutf-8
* @return string 変換後の文字列
public function dec2str($line,$enc='utf-8')
{
$line = preg_replace_callback(
"/(&#[xX]?[0-9a-fA-F]+;)/",
create_function(
'$matches',
'global $enc;'.
'return mb_convert_encoding($matches[0], $enc, \'HTML-ENTITIES\');'
),
$line
);
return $line;
}
10進数でも16進数でも強制的に変換してくれるはずです。
phpdoc風
/**
* 数値文字参照変換メソッド
*
* 10進数、16進数の数値文字参照を文字列に変換する。
*
* @param string line 変換前の文字列
* @param string enc 変換する文字コード 指定しなければutf-8
* @return string 変換後の文字列
public function dec2str($line,$enc='utf-8')
{
$line = preg_replace_callback(
"/(&#[xX]?[0-9a-fA-F]+;)/",
create_function(
'$matches',
'global $enc;'.
'return mb_convert_encoding($matches[0], $enc, \'HTML-ENTITIES\');'
),
$line
);
return $line;
}
FirefoxのアドオンにNoScriptを入れたら Googleツールバーの検索履歴が表示されない [プログラム]
JavaScriptを個別にオンオフできる、FirefoxのアドオンNoScriptを入れたら
Googleツールバーの検索履歴が表示されなくなりました。
そのため、Googleツールバーをいったんアンインストールして、再度
インストールしたら、検索履歴が表示されるようになりました。
悩んでいる方はお試しあれ。
Googleツールバーの検索履歴が表示されなくなりました。
そのため、Googleツールバーをいったんアンインストールして、再度
インストールしたら、検索履歴が表示されるようになりました。
悩んでいる方はお試しあれ。
人気プログラミング言語 [プログラム]
人気プログラミング言語の順位
PHPの順位は3位です。
Rubyは意外と低いですね。
http://journal.mycom.co.jp/news/2010/01/12/022/index.html
PHPの順位は3位です。
Rubyは意外と低いですね。
http://journal.mycom.co.jp/news/2010/01/12/022/index.html
Webminを80番ポートでアクセス可能にする [プログラム]
Webminを80番ポートでアクセス可能にする方法
http://www.webmin.com/apache.html
http://last-resort.seesaa.net/article/123147890.html
Virtual Hostで動作させる。
http://www.webmin.com/apache.html
http://last-resort.seesaa.net/article/123147890.html
Virtual Hostで動作させる。
Oracleメモ [プログラム]
Oracleメモ
SQL Loaderでデータを投入する際
IDはシーケンス(TEST.TEST_NUM_SEQ)自動指定、
入力テーブルはTESTユーザのTEST_NUMBERテーブル、
タブ区切り、
入力文字列はダブルクォーテションの場合
コントロールファイル
INTO TABLE TEST.TEST_NUMBER
FIELDS TERMINATED BY X"09"
(
N_ID "TEST.TEST_NUM_SEQ.NEXTVAL",
"TYPE_NAME" OPTIONALLY ENCLOSED BY '"'
)
タブ区切りのCSVファイル
[tab]"アカサタナ"
[tab]"イキシチニ"
カンマ区切りなら、
コントロールファイルを
FIELDS TERMINATED BY ","
に変更し、
カンマ区切りのCSVファイル
,"アカサタナ"
,"イキシチニ"
参考
http://9po.blogspot.com/2008/06/sqlloaderdb.html
SQL Loaderでデータを投入する際
IDはシーケンス(TEST.TEST_NUM_SEQ)自動指定、
入力テーブルはTESTユーザのTEST_NUMBERテーブル、
タブ区切り、
入力文字列はダブルクォーテションの場合
コントロールファイル
INTO TABLE TEST.TEST_NUMBER
FIELDS TERMINATED BY X"09"
(
N_ID "TEST.TEST_NUM_SEQ.NEXTVAL",
"TYPE_NAME" OPTIONALLY ENCLOSED BY '"'
)
タブ区切りのCSVファイル
[tab]"アカサタナ"
[tab]"イキシチニ"
カンマ区切りなら、
コントロールファイルを
FIELDS TERMINATED BY ","
に変更し、
カンマ区切りのCSVファイル
,"アカサタナ"
,"イキシチニ"
参考
http://9po.blogspot.com/2008/06/sqlloaderdb.html
tracの再構築したが、文字コードエラーが発生 [プログラム]
tracを再構築した際に、UnicodeEncodeErrorが発生する場合は、以下の対処方法が必要です。
pythonのデフォルトの文字コードがasciiのため、発生する現象です。
以下の2行の内容を記述して、
/usr/lib/python2.6/site-package/sitecustomize.pyを作成する。
---ここから---------------------------------------
import sys
sys.setdefaultencoding('utf-8')
---ここまで---------------------------------------
参考
http://d.hatena.ne.jp/SumiTomohiko/20070120/1169300624
pythonのデフォルトの文字コードがasciiのため、発生する現象です。
以下の2行の内容を記述して、
/usr/lib/python2.6/site-package/sitecustomize.pyを作成する。
---ここから---------------------------------------
import sys
sys.setdefaultencoding('utf-8')
---ここまで---------------------------------------
参考
http://d.hatena.ne.jp/SumiTomohiko/20070120/1169300624
Subversionで誤ってコミットによりファイルを追加した場合の削除方法 [プログラム]
Subversionのコミットで、大きなファイルを追加してしまったり、秘密のファイルをアップしてしまったりした場合、特定のリビジョンを削除する方法はないようです。
そこで、これらのファイルが特定できるならば、下記の方法で削除が可能です。
日本語のフォルダ、ファイル名も可能です。
不要なファイル、フォルダ名を指定してダンプします。
#svnadmin dump repo/ | svndumpfilter exclude trunk/間違ったフォルダ/ > back_dump.dat
次に、現在のレポジトリ名を変更します。
#mv repo/ repo_bak/
新たにレポジトリを作成します。
#svnadmin create repo/
先ほど、ダンプしたデータを新たに作成したレポジトリに投入します。
#svnadmin load repo/ < back_dump.dat
これで、フィルタをかけたフォルダ、ファイル以外がレポジトリに反映されます。
そこで、これらのファイルが特定できるならば、下記の方法で削除が可能です。
日本語のフォルダ、ファイル名も可能です。
不要なファイル、フォルダ名を指定してダンプします。
#svnadmin dump repo/ | svndumpfilter exclude trunk/間違ったフォルダ/ > back_dump.dat
次に、現在のレポジトリ名を変更します。
#mv repo/ repo_bak/
新たにレポジトリを作成します。
#svnadmin create repo/
先ほど、ダンプしたデータを新たに作成したレポジトリに投入します。
#svnadmin load repo/ < back_dump.dat
これで、フィルタをかけたフォルダ、ファイル以外がレポジトリに反映されます。
PHPの正規表現チェッカー [プログラム]
PHPの正規表現は、難しいです。
それを解消してくれるサイトがありました。
PHP正規表現チェッカー
http://www.rider-n.sakura.ne.jp/regexp/regexp.php
それを解消してくれるサイトがありました。
PHP正規表現チェッカー
http://www.rider-n.sakura.ne.jp/regexp/regexp.php
Fedora Core 10 でapt-getが失敗する [プログラム]
Fedora Core 10で
#apt-get update
を実行すると下記のようなエラーが出力されました。
******************
apt-get: rpmds.c:518: rpmdsDupArgv: Assertion `argv[ac] != ((void *)0)' が失敗しました.
アボートしました
******************
どうやらrpm関係が悪いみたいなので、
#yum install rpm
とやって、rpm関係をインストールしてやると、
#apt-get update
も、うまく通りました。
#apt-get update
を実行すると下記のようなエラーが出力されました。
******************
apt-get: rpmds.c:518: rpmdsDupArgv: Assertion `argv[ac] != ((void *)0)' が失敗しました.
アボートしました
******************
どうやらrpm関係が悪いみたいなので、
#yum install rpm
とやって、rpm関係をインストールしてやると、
#apt-get update
も、うまく通りました。
Linuxのキーボード [プログラム]
Linuxにおいて起動時のキーボード設定は、
/etc/sysconfig/keyboard
の中に記述してある。
例)
KEYBOARDTYPE="pc"
KEYTABLE="jp106"
これは、日本語キーボードを使用する設定です。
キーボードが出力する信号は、
dumpkeysで、一覧が表示されます。
各キーの信号は、showkeyを使用します。
終了時はCtr+Dです。
# showkey -a
Press any keys - Ctrl-D will terminate this program
| 124 0174 0x7c
: 58 0072 0x3a
^D 4 0004 0x04
キーボード設定の内容は、gzで固められているので、
#zcat /lib/kbd/keymaps/i386/qwerty/jp106.map.gz > jp106.map
で、jp106.mapファイルに出力されるので、これを閲覧すれば可能です。
これは、基本部分の差分ですので、基本部分は、
/lib/kbd/keymaps/i386/include/qwerty-layout.inc
に記載されています。
起動後に一時的に読み込ませるのは、
#loadkeys /lib/kbd/keymaps/i386/qwerty/jp106.map.gz
とすれば、いいのですが、間違った指定をしたときに、結構はまるかもしれません。
/etc/sysconfig/keyboard
の中に記述してある。
例)
KEYBOARDTYPE="pc"
KEYTABLE="jp106"
これは、日本語キーボードを使用する設定です。
キーボードが出力する信号は、
dumpkeysで、一覧が表示されます。
各キーの信号は、showkeyを使用します。
終了時はCtr+Dです。
# showkey -a
Press any keys - Ctrl-D will terminate this program
| 124 0174 0x7c
: 58 0072 0x3a
^D 4 0004 0x04
キーボード設定の内容は、gzで固められているので、
#zcat /lib/kbd/keymaps/i386/qwerty/jp106.map.gz > jp106.map
で、jp106.mapファイルに出力されるので、これを閲覧すれば可能です。
これは、基本部分の差分ですので、基本部分は、
/lib/kbd/keymaps/i386/include/qwerty-layout.inc
に記載されています。
起動後に一時的に読み込ませるのは、
#loadkeys /lib/kbd/keymaps/i386/qwerty/jp106.map.gz
とすれば、いいのですが、間違った指定をしたときに、結構はまるかもしれません。
ejabberdで会議室ログを保存する [プログラム]
ejabberdはJabber/XMPPを実現するサーバ。
Jabberは、
「オープンソースのインスタントメッセンジャーのプロトコルおよび、クライアント、サーバの総称である。」
http://ja.wikipedia.org/wiki/Jabber
XMPPは、
「インスタントメッセージのためのプロトコルの1つ。」
http://ja.wikipedia.org/wiki/Extensible_Messaging_and_Presence_Protocol
ejabberdは、Windows版、Linux版、Mac版があります。
ejabberd
IRCのように会議室を設けてチャットをすることもできる。
ejabberdで会議室ログを保存するには、
ejabberd.cfgの
{modules,
[
...
{mod_muc_log, [
{access_log, muc},
{cssfile, "http://example.com/my.css"}, %%cssの保存場所
{dirtype, plain},
{outdir, "/var/www/ejabberd/muclogs"}, %%ログの保存ディレクトリ
{timezone, local}, %%ログの内容の時刻
{spam_prevention, true},
{top_link, {"http://192.168.0.1:5280/admin/", "ejabberd"}} %%ログ内でリンクするURL
]},
を変更してやればOKです。
これで、/var/www/ejabberd/muclogs/に会議室ごと、日付ごとのHTMLファイルができあがります。
詳しくは、
http://www.process-one.net/en/ejabberd/guide_en#htoc45
全部の会話ログを取得するには、mod_logxmlを使用すればいいみたいですが、試していません。
Jabberは、
「オープンソースのインスタントメッセンジャーのプロトコルおよび、クライアント、サーバの総称である。」
http://ja.wikipedia.org/wiki/Jabber
XMPPは、
「インスタントメッセージのためのプロトコルの1つ。」
http://ja.wikipedia.org/wiki/Extensible_Messaging_and_Presence_Protocol
ejabberdは、Windows版、Linux版、Mac版があります。
ejabberd
IRCのように会議室を設けてチャットをすることもできる。
ejabberdで会議室ログを保存するには、
ejabberd.cfgの
{modules,
[
...
{mod_muc_log, [
{access_log, muc},
{cssfile, "http://example.com/my.css"}, %%cssの保存場所
{dirtype, plain},
{outdir, "/var/www/ejabberd/muclogs"}, %%ログの保存ディレクトリ
{timezone, local}, %%ログの内容の時刻
{spam_prevention, true},
{top_link, {"http://192.168.0.1:5280/admin/", "ejabberd"}} %%ログ内でリンクするURL
]},
を変更してやればOKです。
これで、/var/www/ejabberd/muclogs/に会議室ごと、日付ごとのHTMLファイルができあがります。
詳しくは、
http://www.process-one.net/en/ejabberd/guide_en#htoc45
全部の会話ログを取得するには、mod_logxmlを使用すればいいみたいですが、試していません。


